- 小型模型约5秒
- GPT-J约10秒
- GPT-NeoX约15秒
- 其他大模型约30-60秒
伴随需求同步扩展的解决方案,更快速地提供推理服务
巨门云推理服务提供了一种现代化运行推理的方式,其性能更优,延迟最小,且比其他传统技术平台更具成本效益。
看看我们的解决方案有何不同
传统技术栈
托管云服务
传统云提供商构建的架构是为了满足一般用途和托管环境,而不是计算密集型的用例, 大多具有以下局限:
- 虚拟机主机Kubernetes (K8s),需要通过虚拟机管理程序运行
- 难以扩展
- 启动实例可能需要5-10分钟或更长时间
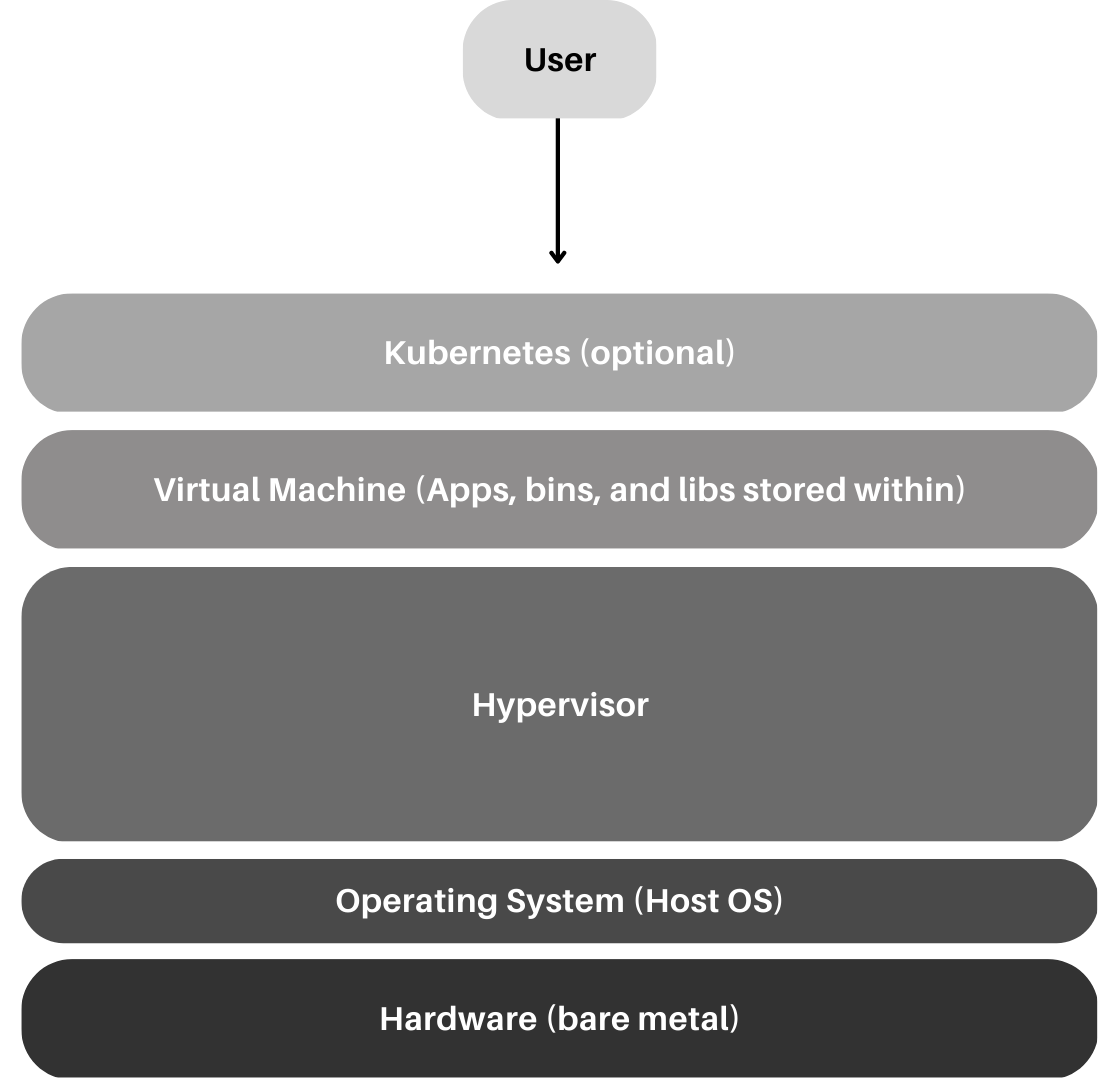
巨门云技术栈
云原生的多模式或无服务器Kubernetes
通过 Kubernetes 部署容器化的工作负载,可以增加可移植性,减少复杂性,并总体上降低成本
- 没有虚拟机管理层,K8s 直接在裸机(硬件)上运行
- 利用Kubevirt在K8s容器内部托管虚拟机
- 方便扩展
- 几秒内启动新实例


自动扩展
为了提高效率和降低成本,优化GPU资源使用
根据需求自动扩缩容器,以迅速满足用户需求,这比依赖于其他云服务提供商的虚拟机实例的扩展要快得多。一旦接收到新的请求,我们可以做到如下的响应速度:
无服务器的Kubernetes
无需担心底层框架的配置是否正确,直接部署模型
KServe 提供了在 Kubernetes 上进行无服务器推理的能力,它为常见的机器学习框架(如 TensorFlow、XGBoost、scikit-learn、PyTorch 以及 ONNX)提供了易于使用的界面,以解决生产环境模型服务的需求


高速网络
开箱即用的高性能现代化网络
巨门云的原生Kubernetes网络设计将功能融入网络结构中,因此您无需管理 IP 和 VLAN,就能获得所需的功能,速度和安全性。
- 轻松部署负载均衡
- 高速接入公网
- 灵活可自定义网络配置


© Copyrights 2022 Merak Technology All rights Reserved.